
This article is part of the 7-part Testing LangGraph Applications series. The examples come from the langgraph-testing-demo repository.
Testing LangGraph Applications Series
- Stop Testing AI Outputs. Start Testing State
- How to Structure LangGraph Tests That Actually Scale
- Testing Isn’t Enough: Evaluating LangGraph Workflows That Actually Work ← You are here
- Testing Parallel LangGraph Workflows Without Losing Control
- Understanding LangGraph Workflows with LangSmith Traces and pytest
- Command vs Send in LangGraph: Choosing the Right Primitive
- What It Takes to Build Production-Ready LangGraph Systems
All examples in this article are backed by a pytest-based evaluation suite, combining deterministic tests with dataset-driven scoring:
In the previous post, we built a proper test suite for a LangGraph workflow.
At this point, the workflow behaves correctly.
- Routing works
- Retries work
- Failures are handled
But correctness only tells you whether the system behaves properly. What it doesn’t tell you is whether the outputs are actually useful.
The Gap Testing Doesn’t Cover
Your tests prove that the system behaves correctly.
For example:
- The reviewer triggers a retry when needed
- The graph stops on failure
- State transitions happen as expected
But they don’t answer questions like:
- Is the research actually useful?
- Is the final output complete?
- Does the answer reflect the user’s intent?
You can pass every test and still ship a system that produces mediocre results, and that’s where evaluation comes in.
From Ad-Hoc Prompts to Repeatable Evaluation
A common workflow looks like this:
Try a prompt → Read the output → Adjust → RepeatThis doesn’t scale. So instead, we move to:
Dataset → Run graph → Score outputsThis gives you a repeatable way to compare outputs over time and see whether changes are actually improving the system.
In this project, the evaluation setup lives in:
demo_graph/evals/dataset.py
demo_graph/evals/evaluators.py
tests/evals/test_langsmith_evals.pyDefining a Dataset
The dataset is intentionally simple and deterministic.
Each example contains:
- An input
- A set of expected terms
For example:
{
"input": "retry path example",
"expected_terms": ["attempt 2", "Final output"],
}This might look basic, but at a minimum, it captures what a useful answer should contain. Not perfectly, but enough to measure progress.
Scoring Outputs
Evaluation starts with a small set of deterministic heuristic functions.
These are intentionally simple:
- Fast
- Reproducible
- Cheap to run
- CI-friendly
For production AI systems, richer evaluation layers can be added, such as:
- LLM-as-Judge evaluators
- Pairwise preference scoring
- Rubric-based grading
- Human review workflows
But deterministic evaluators still provide an extremely useful regression safety net.
For example, a simple completeness score:
def completeness_score(output: str, expected_terms: list[str]) -> float:
normalized_output = output.lower()
matches = sum(
1 for term in expected_terms if term.lower() in normalized_output
)
return matches / len(expected_terms)This produces a score between:
0.0→ nothing matched1.0→ everything matched
Then we wrap it in an evaluator:
def evaluate_example(output: str, example):
return {
"completeness": completeness_score(
output, example["expected_terms"]
)
}This kind of evaluator is intentionally lightweight.
It doesn’t try to deeply understand semantic quality. Instead, it acts as a fast and deterministic regression guard that can run locally, inside CI, or in contributor environments without external dependencies.
A heuristic evaluator might check:
- Whether required concepts appear
- Whether citations exist
- Whether a response follows the expected structure
- Whether tool calls succeeded
An LLM-as-Judge evaluator, on the other hand, can assess things like:
- Relevance
- Helpfulness
- Coherence
- Faithfulness
- Overall response quality
In practice, mature AI systems often combine multiple evaluation layers:
- Deterministic evaluators for stability and regression detection
- LLM-as-Judge evaluators for semantic quality assessment
- Human review for high-confidence validation
Running the Evaluation Loop
The core evaluation loop is simple:
for example in get_dataset():
result = await graph.ainvoke({"user_input": example["input"]})
scores = evaluate_example(result["final_output"], example)This gives you a repeatable way to compare outputs and see how changes affect the system over time.
Using pytest as the Evaluation Runner
One of the most useful patterns here is:
Evaluation runs inside pytest
That means you don’t need a separate system. You simply run:
pytestAnd both:
- Tests (correctness)
- Evaluations (quality)
run together.
The fallback test is named for exactly what it guarantees:
async def test_local_eval_dataset_meets_minimum_completeness() -> None:
graph = build_graph()
for example in get_dataset():
result = await graph.ainvoke({"user_input": example["input"]})
scores = evaluate_example(result["final_output"], example)
assert scores["completeness"] >= 0.5That final assertion is the important part:
assert scores["completeness"] >= 0.5This gives you a simple no-credentials safety net:
- Outputs meet a minimum standard
- Regressions are caught automatically
- Contributors can run the checks without external credentials
LangSmith-Backed Evaluation
The local test isn’t the main evaluation mechanism.
It’s the fallback path: useful in CI, forks, and local development environments where LangSmith credentials are not available. You can still run:
pytestand get a deterministic completeness check.
The primary evaluation path is the LangSmith-backed pytest test. It is skipped
unless LANGSMITH_API_KEY is set, and it uses the LangSmith pytest integration
directly:
@pytest.mark.skipif(
not os.getenv("LANGSMITH_API_KEY"),
reason="LANGSMITH_API_KEY is not set",
)
@pytest.mark.langsmith
@pytest.mark.asyncio
@pytest.mark.parametrize(
"example",
get_dataset(),
ids=lambda example: example["input"],
)
async def test_langsmith_evaluation_logs_dataset_scores(
example: EvaluationExample,
) -> None:
graph = build_graph()
t.log_inputs({"user_input": example["input"]})
t.log_reference_outputs({"expected_terms": example["expected_terms"]})
result = await graph.ainvoke({"user_input": example["input"]})
final_output = result["final_output"]
t.log_outputs({"final_output": final_output})
scores = evaluate_example(final_output, example)
for key, score in scores.items():
t.log_feedback(key=key, score=score)
assert scores["completeness"] >= 0.5At that point, the test is doing more than just tracing the graph.
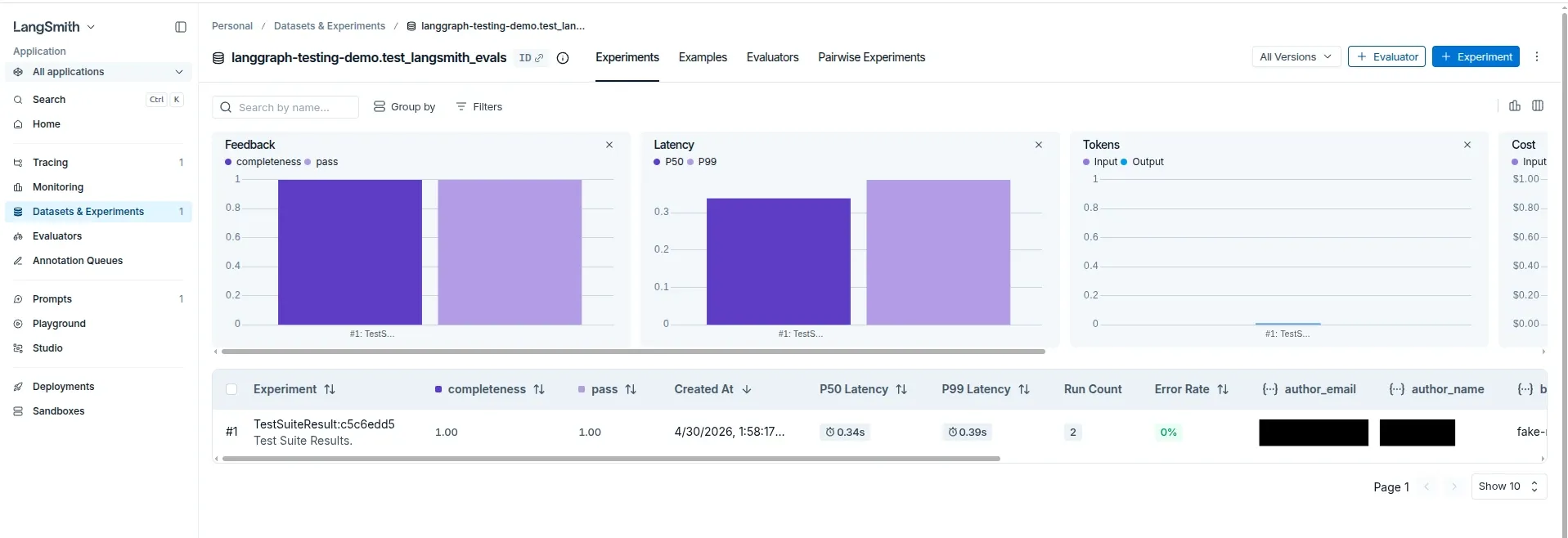
Each dataset row becomes its own parametrized pytest case. For each case, LangSmith receives:
- The input:
{"user_input": ...} - The reference data:
{"expected_terms": ...} - The graph output:
{"final_output": ...} - The deterministic evaluator feedback:
completeness - The pytest pass/fail result
After running the test with LangSmith configured, those examples appear in the LangSmith Datasets & Experiments view:
That gives the project a primary evaluation path and a fallback:
- LangSmith-backed pytest evaluation for tracked examples, scores, and experiment comparison
- Local pytest fallback for fast, portable regression checks when credentials are unavailable
LangSmith Tracing
Tracing focuses on understanding what happened during a graph run.
LangSmith Evaluation
Evaluation focuses on judging the quality of the resulting output for a dataset example.
The refactored test logs inputs, reference outputs, generated outputs, and feedback. That’s what turns the pytest case into a real LangSmith evaluation.
With LANGSMITH_API_KEY set:
- Results are logged externally
- You can track runs over time
- Compare experiments
Without LANGSMITH_API_KEY:
- Everything still runs locally
- No friction for contributors
This keeps the system:
- Portable
- Easy to run
- Not tied to a specific tool
Why Evaluation Helps
Without evaluation:
- Improvements are guesswork
- Regressions go unnoticed
- You rely on manual inspection
With evaluation:
- You can measure change
- You can compare versions
- You can iterate with confidence
You move from:
I think this is better
to:
This version improved completeness from 0.5 to 0.8
Testing vs Evaluation (Clear Separation)
It’s important to keep this distinction clear:
Testing
- Validates correctness
- Deterministic
- Focused on behavior
Evaluation
- Measures quality
- Often heuristic
- Focused on usefulness
In this project:
- pytest handles both
- But the responsibilities are separate
If your tests depend on output quality, they will fail for the wrong reasons. If you skip evaluation, you won’t know if your system is improving.
A Practical Way to Evolve This
This example intentionally starts with deterministic heuristics because they’re:
- Easy to understand
- Easy to debug
- Cheap to run
- Stable in CI
In a real system, you would likely evolve this further with:
- Larger and more representative datasets
- More nuanced scoring strategies
- LLM-as-Judge evaluators for semantic quality assessment
- Pairwise preference comparisons
- Human review workflows
But the structure stays the same:
Dataset → Run graph → Score outputs → Track resultsThe evaluation layer becomes more sophisticated over time, but the workflow itself remains stable.
Why You Need Both
- Testing helps ensure the workflow behaves correctly.
- Evaluation helps determine whether the outputs are actually useful.
In practice, production systems usually need both.
What’s Next
In the next post, we’ll push this further by introducing:
- Parallel execution with multiple workers
- Aggregation patterns
- New failure modes
- And how to test all of it
Spoiler alert: Parallel execution introduces a whole new set of testing problems.
Final Thought
AI systems generally improve once their outputs can be measured and compared consistently over time.
That’s when iteration becomes much more engineering-driven instead of relying on intuition alone.